 Home-theater-designers
Home-theater-designers
Ca analist de date, te vei confrunta adesea cu nevoia de a combina mai multe seturi de date. Va trebui să faceți acest lucru pentru a vă finaliza analiza și a ajunge la o concluzie pentru afacerea dvs./părțile interesate.
Este adesea dificil să reprezentați datele atunci când sunt stocate în tabele diferite. În astfel de circumstanțe, alăturarile își dovedesc valoarea, indiferent de limbajul de programare la care lucrați.
REALIZAREA VIDEOCLIPULUI ZILEI
Alăturarile Python sunt ca și alăturarile SQL: combină seturi de date prin potrivirea rândurilor lor pe un index comun.
Creați două cadre de date pentru referință
Pentru a urma exemplele din acest ghid, puteți crea două exemple de DataFrame. Utilizați următorul cod pentru a crea primul DataFrame, care conține un ID, un prenume și un nume.
import pandas as pd
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber"]})
print(a)Pentru primul pas, importați panda bibliotecă. Apoi puteți utiliza o variabilă, A , pentru a stoca rezultatul din constructorul DataFrame. Transmiteți constructorului un dicționar care conține valorile necesare.
În cele din urmă, afișați conținutul valorii DataFrame cu funcția de imprimare, pentru a verifica că totul arată așa cum v-ați aștepta.
În mod similar, puteți crea un alt DataFrame, b , care conține un ID și valori salariale.
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(b)Puteți verifica rezultatul într-o consolă sau un IDE. Ar trebui să confirme conținutul DataFrame-urilor dvs.:
Prin ce sunt diferite uniunile de funcția Merge din Python?
Biblioteca Pandas este una dintre bibliotecile principale pe care le puteți folosi pentru a manipula DataFrames. Deoarece DataFrames-urile conțin mai multe seturi de date, diferite funcții sunt disponibile în Python pentru a le alătura.
Python oferă funcțiile de îmbinare și îmbinare, printre multe altele, pe care le puteți utiliza pentru a combina DataFrames. Există o diferență puternică între aceste două funcții, de care trebuie să țineți cont înainte de a utiliza oricare dintre ele.
Funcția de unire unește două DataFrames pe baza valorilor lor de index. The funcția de îmbinare combină DataFrames pe baza valorilor indexului și a coloanelor.
Ce trebuie să știți despre asocieri în Python?
Înainte de a discuta despre tipurile de alăturari disponibile, iată câteva lucruri importante de reținut:
- Uniunile SQL sunt una dintre cele mai de bază funcții și sunt destul de asemănătoare cu îmbinările lui Python.
- Pentru a vă alătura DataFrames-ului, puteți utiliza pandas.DataFrame.join() metodă.
- Uniunea implicită realizează o îmbinare la stânga, în timp ce funcția de îmbinare realizează o îmbinare internă.
Sintaxa implicită pentru o îmbinare Python este următoarea:
DataFrame.join(other, on=None, how='left/right/inner/outer', lsuffix='', rsuffix='',
sort=False)Invocați metoda join pe primul DataFrame și transmiteți al doilea DataFrame ca prim parametru, alte . Argumentele rămase sunt:
- pe , care denumește un index la care să se alăture, dacă există mai mult de unul.
- Cum , care definește tipul de îmbinare, inclusiv interior, exterior, stânga și dreapta.
- lsufix , care definește șirul de sufix din stânga al numelui coloanei dvs.
- rsufix , care definește șirul de sufix drept al numelui coloanei dvs.
- fel , care este un boolean care indică dacă trebuie sortat DataFrame rezultat.
Învață să folosești diferitele tipuri de îmbinări în Python
Python are câteva opțiuni de alăturare, pe care le puteți exercita, în funcție de nevoia orei. Iată tipurile de unire:
1. Left Join
Alăturarea din stânga păstrează intacte valorile primului DataFrame, aducând în același timp valorile potrivite din al doilea. De exemplu, dacă doriți să introduceți valorile potrivite de la b , îl puteți defini după cum urmează:
cum se deschide unitatea flash pe Windows 10
c = a.join(b, how="left", lsuffix = "_left", rsuffix = "_right", sort = True)
print(c)Când se execută interogarea, rezultatul conține următoarele referințe de coloane:
- ID_left
- Fname
- Lname
- ID_dreapta
- Salariu
Această îmbinare trage primele trei coloane din primul DataFrame și ultimele două coloane din al doilea DataFrame. A folosit lsufix și rsufix valori pentru a redenumi coloanele ID din ambele seturi de date, asigurându-vă că numele câmpurilor rezultate sunt unice.
Ieșirea este după cum urmează:

2. Alăturați-vă dreapta
Uniunea din dreapta păstrează intacte valorile celui de-al doilea DataFrame, aducând în același timp valorile potrivite din primul tabel. De exemplu, dacă doriți să introduceți valorile potrivite de la A , îl puteți defini după cum urmează:
c = b.join(a, how="right", lsuffix = "_right", rsuffix = "_left", sort = True)
print(c)Ieșirea este după cum urmează:
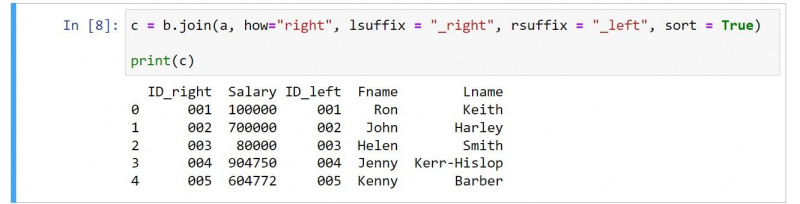
Dacă examinați codul, există câteva modificări evidente. De exemplu, rezultatul include coloanele celui de-al doilea DataFrame înaintea celor din primul DataFrame.
Ar trebui să utilizați o valoare de dreapta pentru Cum argument pentru a specifica o alăturare dreaptă. De asemenea, rețineți cum puteți comuta lsufix și rsufix valori pentru a reflecta natura uniunii drepte.
În îmbinările tale obișnuite, s-ar putea să te trezești că folosești îmbinările din stânga, interioare și exterioare mai des, în comparație cu alăturarea dreaptă. Cu toate acestea, utilizarea depinde în întregime de cerințele dvs. de date.
3. Imbinare interioara
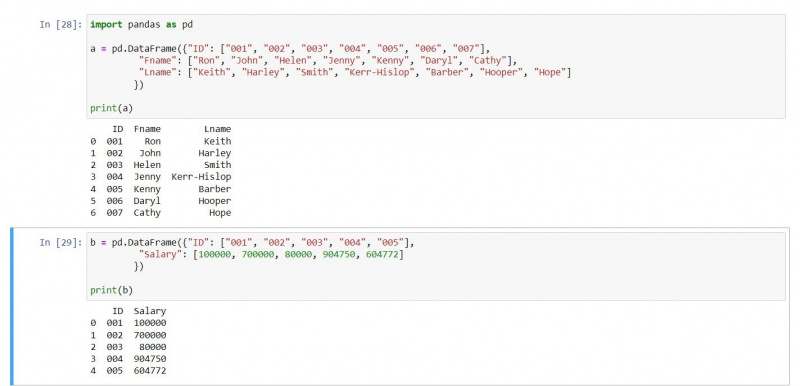
O îmbinare internă furnizează intrările care se potrivesc din ambele DataFrames. Deoarece îmbinările folosesc numerele de index pentru a potrivi rândurile, o îmbinare internă returnează numai rândurile care se potrivesc. Pentru această ilustrare, să folosim următoarele două DataFrames:
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005", "006", "007"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny", "Daryl", "Cathy"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber", "Hooper", "Hope"]})
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(a)
print(b)Ieșirea este după cum urmează:
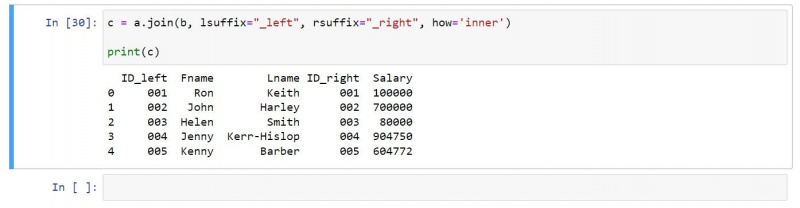
Puteți utiliza o îmbinare interioară, după cum urmează:
la ce se folosește zmeura pi
c = a.join(b, lsuffix="_left", rsuffix="_right", how='inner')
print(c)Ieșirea rezultată conține numai rânduri care există în ambele DataFrames de intrare:
4. Îmbinare exterioară
O îmbinare exterioară returnează toate valorile din ambele cadre de date. Pentru rândurile fără valori care se potrivesc, produce o valoare nulă pentru celulele individuale.
Folosind același DataFrame ca mai sus, iată codul pentru îmbinarea exterioară:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='outer')
print(c)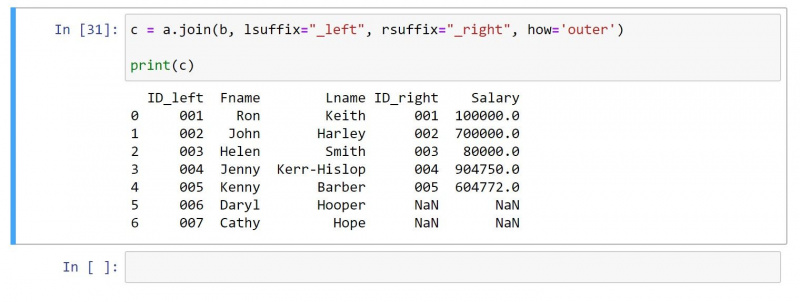
Utilizarea Joinurilor în Python
Unirile, ca și funcțiile lor omoloage, merge și concat, oferă mult mai mult decât o simplă funcționalitate de alăturare. Având în vedere seria sa de opțiuni și funcții, puteți alege opțiunile care corespund cerințelor dumneavoastră.
Puteți sorta seturile de date rezultate relativ ușor, cu sau fără funcția de unire, cu opțiunile flexibile pe care le oferă Python.